
Peeking Inside the AI Black Box
Mechanistic interpretability and how we might be able to understand the inner workings of the AI "mind"

LLMs have a “black box problem” - they’re opaque and often work in mysterious ways. Models have “hallucinations”, where they generate incorrect or misleading results. We’ve somehow wound up with these extremely powerful and useful tools that can write essays, code software, and solve complex problems. Yet, when you peek under the hood, it’s almost impossible to understand their inner workings or trace an output back to their origins.
LLMs, like those used in ChatGPT or Gemini, aren’t programmed line-by-line by human engineers. Instead, they learn autonomously from vast amounts of data. We can’t easily pinpoint bugs or errors. In many ways, they are “grown” more than “built”. If we don't know how these systems work, how can we possibly make them safe?
But there is some good news! Last month, both OpenAI and Anthropic made pretty huge breakthroughs and published new research in this space. We’re making leaps forward in “mapping the mind” of LLMs, allowing us to open up the AI black box for closer inspection. Let’s break down these technical advancements and explore how they bring us closer to understanding and improving AI safety!
Full papers for the curious minds:
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Anthropic)
Extracting Concepts from GPT-4 (OpenAI)
Why It Matters
This breakthrough is a game-changer because we can further improve safety and increase reliability, especially when the misbehavior of AI models raises concerns about potential threats (bioweapons, propaganda, cyberattacks - the stuff of sci-fi nightmares). If certain features can be turned on or off, this could prevent the model from being deceptive or biased. Currently, AI safety is like playing whack-a-mole - we can only evaluate an output after it’s generated, a reactive approach. This research means we might be able to intercept and correct bad behavior in real-time, before it outputs.

The mapping they’ve completed in this research is just a small fraction of the billions of features that models contain, but it’s an important step in making these models “safer” for human use. By understanding AI models better, we can improve our control of and confidence in their use.
LLMs Explained
Traditional code is linear and predictable – you input instructions with explicitly defined functions and rules, and get an expected outcome. LLMs are less predictable. They don’t just follow instructions: they take in vast amounts of data, adapt based on a model’s architecture, and learns and develops on its own through the training process. It’s much more akin to the way biological organisms grow and evolve vs. being built.
Mechanistic interpretability, then, is like studying the biology of the language models. It is the study of understanding AI models' decision-making processes. However, until recently, it has been largely theoretical and small-scale, making steady but slow progress.
Maze within a Maze within a Maze
This is an oversimplification, but think of a LLM like a giant maze with many twists and turns - think “Inception” level “maze within a maze within a maze”. When you give it an input (a question), it travels through this maze to find an output (an answer).

Why can’t we just trace our way? Unfortunately, this complex maze has a couple twists:
# of Possible Paths: It has millions of paths (made up of thousands of tiny steps) it can take to come up with an answer. Each path is like a different way it can think about the question.
Hidden Layers and Invisible Paths: Unlike a regular maze, these paths are invisible and happen in hidden layers inside the model, making it difficult to see how you got from point A to point B. Each layer transforms the information in ways that are hard to see and understand.
Interconnected Paths: The paths are highly interconnected. One input can influence many different parts of the model, leading to an output that’s influenced by many different factors.
Making It Make Sense
The researchers figured out that the LLM maze/brain actually has many “light bulbs” that light up at each step when it thinks about different things. They identified about 10 million of these patterns - “features” - that correspond to real concepts that we can understand. Some light bulbs might flicker for simple ideas like “cat” or “dog”, while other combinations light up for complex ideas like “vacation” or “science”.

To make sense of the “lights”/thoughts, researchers have developed a special method to see which part of the LLM is active when it thinks about specific things. They use a technique called "sparse autoencoders" to train the model to break down its complex inputs into clear and understandable pieces - in simple, small chunks instead of jumbled ideas. (eg. if you show a picture of a cat, only a few neurons related to “animal”, “meow”, “fur”, “four legs” might light up. Like thinking in bullet points instead of stream-of-consciousness rambling.)
They found that models can have clear thoughts about specific things:
Golden Gate Bridge Feature: if you ask the model about "San Francisco landmark" or “famous bridge in California” the same pattern of lights that represents the Golden Gate Bridge will blink. This tells researchers that the model is thinking about the Golden Gate Bridge, even if the exact words weren't mentioned.

Brain Science: if you ask the model “how the brain functions” or “cognitive science”, a pattern of lights that represent brain science will blink, showing that it can understand and respond to queries related to this field accurately and contextually.


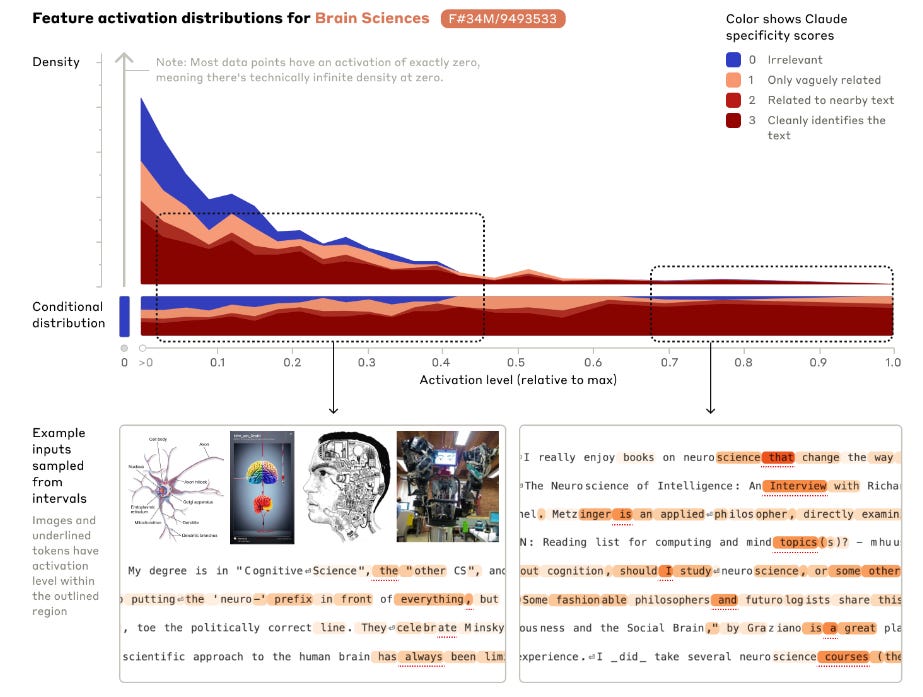
Influencing Behavior
If we can control which light bulbs light up, the researchers can influence how a model behaves. We can influence what it talks about by tweaking the intensity of certain features (feature steering). Let’s use the same example:
The researchers can artificially increase the brightness of the Golden Gate Bridge light bulb → the model becomes very focused on the Golden Gate Bridge. It might start talking a lot more about the bridge, even if you only mentioned something related to San Francisco.

You can already do some version of this where you give a model custom instructions (“please emphasize the Golden Gate Bridge and make it highly relevant to your output”) and it will produce a similar answer. This works in a different, more direct way, like supercharging one part of the model. By “clamping” different light bulbs to artificially high or low values, we can:
Test Influence: Understand what each light bulb does and how it influences the model. We can find out which light bulbs are connected to biases, deceptions or manipulations, and dangerous content.
Improve Accuracy: If the model consistently talks about a concept when certain lights bulbs are bright, we can confirm that the feature is correctly linked to that concept.
Control Behavior: If we want the model to be more focused on safety, we can “clamp” the features related to safety topics - sort of like being able to turn up the “caution” dial on an AI’s decision-making process.
What does this mean for Safety?
Beyond identifying and turning off bad features, there’s more to how this can make models safer. One very straightforward application is monitoring the model’s behavior in real-time.
Real-time Detection: By monitoring whenever an AI performs an unwanted action (eg. writing a scam email), you can instantly detect when the AI is doing something undesirable and stop it before it completes the action.

Behavior Tracking: By tracking how the AI’s behavior changes over time (eg. shifts between different personas or ways of acting), you can adjust the model’s training to prevent unwanted behaviors before they happen.
Reason for Answer: Why the model gave a particular output matters. Is it lying because it knows the truth but chose to mislead, or is it making a guess because it doesn’t know the answer? Understanding the reason can help us address different problems appropriately.
Proactive Interception: Currently, AI safety often involves evaluating the output after it has been generated. This is a reactive approach where humans or automated systems check if the output is safe or violates any rules. This research allows for intercepting and correcting bad behavior while the model is still processing the input → intervening upstream in the decision-making process.

As models hallucinate, many of us question “why does this happen?”. It can be frustrating to see even the brightest minds at AI powerhouses shrug their shoulders and admit, “we have no idea” or “we’re working on it”. This groundbreaking research is brings us a little closer to answering these questions than we were a few months ago. We’re getting closer to understand the “why” of AI behavior, not just the “what” - hopefully making this technology safer, fairer, and more transparent. Onward and upward!

I hope this dive into the AI mind maze was as interesting for you as it is for me, despite its technical nature. Let us know if you'd like more breakdowns on the tech behind all this AI frenzy (and if so, what topics you have the most questions on).