


Observations from the AI Model Olympics
A summer of breakthroughs in open-source, small language models, domain specialization + what's coming

Just as nations battled it out for dominance on the Olympic medal table in the last two weeks, leading AI research labs and foundation model providers have been locked in their own high-stakes technological Olympiad this summer. In both arenas, we've witnessed a breathtaking sprint of progress: athletes breaking new world records and AI models leaping over benchmarks that seemed insurmountable mere months ago.
This AI Summer has been marked by a flurry of releases from major players in the field. It seems that every few weeks now, one of the big AI players releases a new model or variation, with improvements in cost, performance, or other key attributes.

Amidst these rapid developments, several key innovation vectors are emerging in the evolution of foundation models. These vectors represent the directions in which AI capabilities are expanding to meet a range of evolving needs across consumer and enterprise verticals. We dive into a couple trends we’re observing:
Open Source:
Small Language Models
Domain Specialization
Key Takeaways
What’s Next? (Multimodality, Agentic Capabilities, AI Scaling Plateau)
Open Source
Open source AI is reaching a significant turning point - one that could accelerate global AI development, reshape industries, and alter the current competitive landscape.
In the last month, two major developments reaffirmed the growing capabilities of open source models and challenged the long-held dominance of proprietary systems:
Meta’s Llama 3.1: A 402B parameter model that scored at GPT-4o levels (across general knowledge, steerability, math, tool use, and multilingual translation). It comes in 8B, 70B, and 405B variants, all natively multilingual and support tool calling. The 405B model excels in generating smaller, task-specific models, while its 128k context window makes it ideal for RAG applications. Mark Zuckerberg declared that it had achieved “frontier-level” status. (Though the AI field is known for its shifting benchmarks, so “frontier-level” is really more of a moving target.)
Mistral Large 2: Released just a day after Llama 3.1, Mistral's latest flagship LLM boasts 123B parameters and a 128k context window. Supporting dozens of languages and 80+ coding languages, it competes with leading models in code generation and reasoning. Mistral Large 2 represents a more reliable, less hallucinatory upgrade to its predecessor, excelling in complex tasks and long, multi-turn conversations.

What makes open source different?
Put simply, open source software is the opposite of proprietary software - it’s (1) open and transparent, and (2) often developed and owned by a community (vs. a single corporation). Key benefits include:
Cost-efficiency: No licensing fees or subscription costs.
Quick to deploy: Freely available with minimal integration required.
Modifiability and Customization: Allows developers to easily modify and fine-tune to meet specific needs.
Sustainability: Reduced vendor lock-in, giving organizations control over their own technology stack and the flexibility to move between different tools and platforms.
Note: Open source doesn't imply unrestricted use. Licensing terms can impose conditions on usage, distribution, and naming conventions (e.g. all Llama-based models must include "Llama" in their name).
Historically, leading AI companies kept their most advanced models private, citing concerns over safety, potential misuse, and competitive advantage. This shift towards open source is forcing established leaders to reconsider their approach to transparency. While it could potentially accelerate the overall pace of AI development and democratize access, it also reignites debates over open source vs. closed development.
Zuckerberg, waving the open source flag high, argues that open source development is the best approach not only for Meta’s business, but for the world at large. By open-sourcing such a powerful model, Meta aims to accelerate its own AI development through global collaboration, potentially saving costs and improving its systems.
Meta's long-term strategy appears twofold: (1) position itself to profit from an ecosystem of tools and services built around free core AI models, while (2) challenge competitors by offering comparable technology at zero cost - a “commoditize your complement” strategy.
Foundation model developers (OpenAI, Anthropic, DeepMind) make money by selling access to their models - what happens in a world where Meta (which already has a multi-billion dollar ad business) can give AI away for free?

“The bottom line is that open source AI represents the world’s best shot at harnessing this technology to create the greatest economic opportunity and security for everyone.” - Mark Zuckerberg
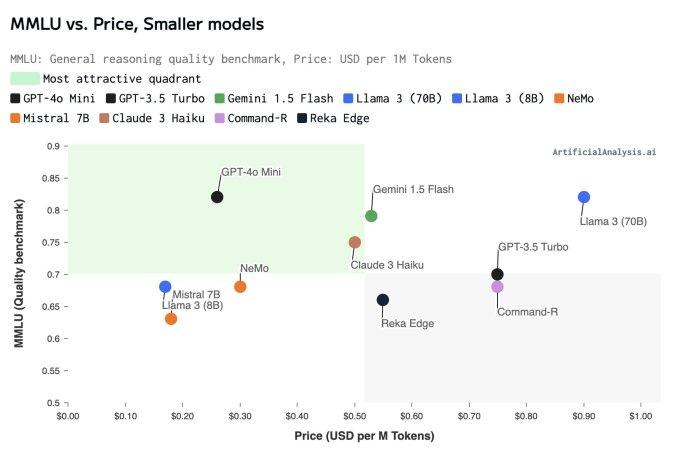
Small Language Models
While giants like GPT-4 and Gemini Ultra command attention with their massive scale and eye-watering training costs ($78M and $191M respectively), a countermovement is gaining traction.
SLMs prove that bigger isn’t always better. They offer many capabilities of larger models but in a smaller, more cost-effective, and user-friendly package. They are accessible to organizations with limited resources and are easier to use and deploy. They’re particularly suited for specific tasks and applications, providing faster adaptation to particular datasets or applications.
OpenAI’s GPT-4o Mini: A cost-efficient small model designed to make AI more accessible by reducing costs while maintaining high performance. It's 20x cheaper than GPT-4o with equivalent performance and 60% cheaper than GPT-3.5 Turbo. The model surpasses GPT-3.5 Turbo and other small models in textual intelligence and multimodal reasoning. It's also 2X faster than GPT-4o and GPT-3.5 Turbo, making it ideal for high-volume, speed-dependent tasks like customer support chatbots.
DeepMind’s Gemma 2 2B: A 2B parameter AI model optimized for hardware efficiency, surpassing its predecessor by over 10% in benchmarks and even outperforming larger models like GPT-3.5. Balancing performance and efficiency, Gemma 2 2B is ideal for edge devices, laptops, and on-device applications with limited hardware resources. The model can process up to 2 trillion tokens and excels in robust conversational AI tasks. Notably, it's also open source.
Apple’s OpenELM and Apple Intelligence Models: OpenELM consists of eight efficient language models, ranging from 270M to 3B parameters. They are designed to run locally on devices like smartphones, preserving data privacy. They are fine-tuned for everyday tasks and can adapt to users' current activities.
“LLM model size competition is intensifying… backwards!” - Andrej Karpathy
Domain Specific
While general-purpose foundation models (like GPT-4o or Claude 3.5 Sonnet) are trained on massive, diverse datasets, they can fall short for those seeking industry-specific solutions. Enter domain-specific models, which use large amounts of training data within a specific field or industry (e.g. healthcare, finance, education, law).
These specialized models often outperform their general counterparts in niche areas, offering improved accuracy, faster results, and more cost-effective solutions for industry-specific problems. They can achieve meaningful results with less data, making them more accessible and practical for a wider range of applications.
Alibaba’s Qwen2-Math: A 72B parameter math model that outperforms all open and closed models on the MATH benchmark. Trained on a comprehensive mathematics-specific corpus, it excels in complex mathematical tasks, with bilingual support forthcoming.
Mistral’s Codestral Mamba and MathΣtral: Codestral Mamba is a cutting-edge code generation model demonstrating strong performance across multiple programming languages. MathΣtral (pronounced "Mathstral") is designed specifically for mathematical reasoning and scientific discovery, fine-tuned to excel in STEM subjects. The model's name pays tribute to Archimedes.
Google’s LearnLM: A family of generative AI models “fine-tuned” for learning. Built on top of Google’s Gemini models, LearnLM models are designed to conversationally tutor students on a range of subjects. They used a mix of human tutoring data, AI generated student-tutor roleplay data, step-by-step math solutions in conversational format, and high-quality conversations demonstrating the desired pedagogical behaviors.
In education, domain-specific AI models (like LearnLM) can be fine-tuned to meet the unique needs of different educational contexts. These models can integrate educational theories and pedagogical best practices, making them more effective at assessing student performance in ways that align with specific educational objectives. By specializing in particular subjects or areas of study, these models can offer more accurate assessments, provide targeted feedback, and deliver tailored content recommendations.
Key Takeaways
Democratization of AI: The gap between open-source and proprietary AI models has narrowed significantly, allowing smaller companies and individual developers to access sophisticated AI capabilities without hefty costs or vendor lock-in.
Bigger Isn’t Always Better: The industry is seeing strong downward pressure on model size - they're shrinking! This trend challenges the conventional wisdom that bigger models are always superior.
Diversification: Businesses can now choose from a variety of AI models, including Small Language Models (SLMs) and domain-specific models, to best fit their specific needs, balancing performance with cost and resource requirements.
AI in Your Pocket: SLMs enable AI functionality on devices with limited resources, enhancing privacy through local data processing and reducing reliance on continuous internet connectivity. Education apps and tools can process student data locally, ensuring compliance with data protection regulations in education.
Jack of All Trades Meets Master of One: Domain-specific models offer improved efficiency and performance in targeted areas, allowing organizations to optimize resource allocation for maximum impact = faster results with less computational overhead.
David vs. Goliath: AI labs and foundation model providers must now grapple with how to differentiate themselves in a world where cutting-edge AI capabilities are becoming increasingly commoditized (and freely available).
Ethical Considerations: The rise of open-source AI raises concerns about potential risks, necessitating ongoing discussion to balance innovation, safety, and ethics in AI development. What happens when we lower the barriers for actors with less-than-noble intentions to exploit these powerful tools?
What’s coming?
Multimodality
Multimodal Large Language Models (MLLMs) are advanced models that can process and understand multiple types of input data, including text, images, audio, and video. By integrating language and vision components, MLLMs enable applications such as visual question answering, image captioning, and multimodal dialogue systems. Despite their powerful capabilities, researchers are still figuring out how to reduce computational costs and address the need for high-quality multimodal data sets.
The future of AI lies in creating systems that understand our world in all its complexity. By bridging the gap between language and vision (and perhaps even our other senses of touch, taste, and smell), MLLMs are bringing us closer to AI systems that can truly see, understand, and communicate about the world as humans do.
Notable developments: Gemini 1.5 0801, ML-Mamba, GPT-4o Mini, Claude 3.5 Sonnet
Agentic Capabilities
AI agents are designed to autonomously perform tasks, make decisions, and adapt to new information in real-time. Unlike traditional AI models that simply respond to commands, agents can proactively solve problems and execute tasks without constant human intervention. These agents are able to create step-by-step plans, learn from feedback, and efficiently solve complex problems by using short-term memory and long-term data to maintain context and inform future decisions and interactions.
AI agents are NOT AI models themselves, but rather complex systems that use the capabilities of AI models as a foundation and extend their functionality through various mechanisms.
Recent model developments have significantly enhanced the capabilities of AI agents, particularly in areas like function calling and task execution. This means that AI models are getting more adept at generating structured outputs and more accurately interacting with other tools and APIs. Models are also improving in their ability to decide when and how to use external tools, while also maintaining context across interactions, enabling them to effectively handle complex tasks and multi-turn conversations.
These structured outputs and improvements in tool utilization allow AI agents to break down complex tasks more effectively and utilize appropriate resources to accomplish goals.
Notable developments: Groq’s Llama-3-Groq-Tool-Use, Apple’s 4M-21
A Potential AI Scaling Plateau?
AI scaling laws suggest that as AI models become larger (in parameters and training data), their '“performance” typically improves. Training compute of frontier AI models has grown by 4-5x per year since 2010, aligning with the impressive performance gains we‘ve seen from frontier models in recent years. However, there's a looming question of how long this trend will continue:
This relationship often follows a power-law pattern: larger models → performance gains. As models get bigger, gains in performance might not always follow the same predictable pattern.
Training AI models requires large amounts of data, often sourced from human-created text or other forms of content. Researchers are already estimating when we’ll run out of human-generated training data (they project 2028).
There may come a point where it's not possible to continue scaling by “throwing more compute at the same data”. For one, it might become too expensive - the CEO of Anthropic predicted that the cost to develop the next generation of AI systems to be released later this year would be around $1B.
What exactly is a “better” model? Scaling laws only quantify the decrease in perplexity, that is, improvement in how well models can predict the next word in a sequence. Of course, perplexity is more or less irrelevant to end users — what matters is “emergent abilities”, that is, models’ tendency to acquire new capabilities as size increases. - AI Snake Oil
There’s no clear answer on when or if we’ll even hit this scaling ceiling. If the AI industry sticks on this path, perhaps AGI might indeed be ‘strikingly plausible’ by 2027. If it doesn’t, achieving AGI could become a much longer and more complex endeavor.
However, this potential plateau in AI scaling raises critical questions about the future direction of AI R&D. Will we see a shift towards more efficient architectures? Or a renewed focus on novel training techniques and data curation? The answers to these questions could shape the trajectory of AI progress for years to come.
Further reading: Azeem Azhar explains the scaling ceiling and Dwarkesh Patel has a great overview on different sides of this debate.

Parting Thoughts
While Olympics has come to an end, the AI race is far from over. Each development brings us closer to realizing the transformative potential of AI. Whether through open-source collaboration, efficient small models, data innovations, or pushing the boundaries of scale, the quest to advance AI capabilities shows no signs of slowing down.
As we look ahead, it's clear that the future of AI isn't purely about raw power and compute - it's also about building for precision, efficiency, and accessibility. The question isn't just "How big can we make it?" but "How smart can we make it, and for whom?"
One thing is certain: the world of AI will look very different by the time the next Summer Games roll around.
Very comprehensive and insightful! Already shared with colleagues. Thank you very much!
!!!!